


Prompts are lying to you
Combining prompt engineering with DSPy for maximum control

🚨 Alert. This article is dangerously practical—no AI buzzword bingo here. Oh, and did I mention? We have CODE. 🧑💻
Oh, and one more thing… we’re now on 🔗 LinkedIn! Follow for snippets of knowledge.
Key takeaways
Prompts shape the AI’s behavior and should be evaluated just as much as models do.
The old method of hardcoded prompts fails to scale, is slow and rigid.
DSPy introduces modular and programmable prompts which in turn allow for reproductive AI workflows.
I've always been passionate about building production AI systems. With GenAI's rapid rise, the need for clear, high-quality guidelines on how to approach production-ready GenAI systems has never been more critical.
In the last 2 years, prompt engineering has been treated as an afterthought, a means to an end.
In many circles, the prompt is often seen as just text.
But in reality, a prompt is the most crucial hyperparameter of any GenAI system. Its design can make or break the output quality, much like tuning a model's parameters determines its performance.
I’ve seen so many systems where prompts are treated badly without considering that prompts need structure → input, context, and output.
In the end, we must prepare our prompting system for observability and future versioning.
Traditional prompt engineering often involves manually crafted templates, built with trial and error, that struggle to scale in complex production environments.
In this article, we will explore how combining classical prompt templates with DSPy transforms that process.
By leveraging DSPy’s declarative signatures and modular pipelines, we can move beyond brittle, ad-hoc prompts and achieve a level of control and optimization that is simply unattainable with traditional methods.
This will be a 2-part series:
Part 1 → where I will discuss about how I migrated from prompt templates to Dspy;
Part2 → where we go deeper into Dspy with a practical end-to-end example.
Table of Contents
Prompts → the most important hyperparameter in GenAI systems
The Impact of prompt design on output quality.
Chat models vs reasoning models
Reimagining prompt engineering with DSPy
Old school way of treating prompts
DSPy Paradigm: Let’s program — not prompt — LMs
Practical case study → create a summary of a long document
Conclusion
1. Prompts: one of the most important hyperparameters in GenAI systems
Imagine trying to train a dog without clear commands. You say "fetch," but sometimes you mean "sit." Other times, you mutter words and hope it gets the idea. That’s how many AI engineers treat prompts—random tweaks, hoping for the best.
But here’s the truth: a prompt is one of the most essential hyperparameters in your GenAI system. It’s not just text; it’s the key that unlocks the AI’s potential. Just like fine-tuning a model requires careful data selection, your prompts need the same structured approach.
If you don’t define them properly, you risk overfitting the prompt to your data—a silent problem that makes your AI seem smart in testing but fail miserably in the real world.
Think about it: Every time you change a prompt, you adjust the AI’s behavior without realizing it. It might work perfectly on one dataset but fail on unseen cases.
That’s why prompt validation is just as important as model validation. Before trusting your AI’s performance, you need to test your prompts against a validation set, just like you would with a fine-tuned model.
Yet, most AI teams don’t do this. They write a prompt, test it on their current data, and assume it’s good. But without structured evaluation, they’re blindly shaping AI behavior with no way to measure success.
2. The impact of prompt design on output quality
There are several resources about how you can write the perfect prompt. As you know, we have different techniques for writing prompts, but I like to classify this process into two categories:
Prompts for reasoning LLM models
Prompts for chat LLM models
When comparing prompt methods for chat models versus reasoning models, it is essential to understand their distinct purposes and the techniques that best suit each.
Chat models, such as GPT-4, are optimized for conversational tasks and generating coherent, contextually appropriate responses. These models excel in answering questions, summarizing text, or creative writing. Prompting techniques for chat models often focus on providing examples or role-playing to guide their behavior.
Reasoning models, such as OpenAI’s O1-series or similar advanced reasoning-focused LLMs, are designed for complex problem-solving tasks requiring logical steps or deep analysis. These models perform internal reasoning processes and are better suited for tasks like mathematical problem-solving, legal analysis, or multi-step reasoning.

There is no perfect formula for writing the best prompt, in my opinion. You must understand what task you want to achieve and start iterating on that.
The most important thing that must be considered is the type of LLM for which you create prompts.
For the chat models, my favorite framework is the 3Cs:
👇👇👇

For the reasoning models, use this prompt anatomy:
👇👇👇

3. Re-imagining prompt engineering with DSPy
3.1. Old school way of treating prompts
Enough theory, right? Knowledge is power, but theoretical knowledge without practical implementation is nothing.
Before explaining DSPy and why I migrated an entire code base to this framework; let’s go back in time and see how prompts were treated, or at least how I used to do it.
Before migrating to DSPy, I handled prompts in a way that would feel familiar to most AI engineers: using hardcoded templates and manual structuring. Each prompt was a carefully written piece of text, embedded inside a function or a class, guiding the LLM to produce the correct output. While this approach worked, it had several limitations that became obvious as my system scaled.
query_category.py
from retrieval.core.interfaces import BasePromptTemplate
class QueryCategory(BasePromptTemplate):
prompt: str = """
Analyze the user query below and categorize any sub-questions into two types:
1. Document/email-specific questions (i.e., answers found within the provided text)
2. General-knowledge questions (i.e., answers requiring information beyond the provided text)
Important details:
- A single user query may contain multiple sub-questions.
- If a sub-question can be answered directly from the provided text, categorize it under "rag_queries."
- If a sub-question requires external or general knowledge, categorize it under "general_queries."
- If a sub-question clearly needs both the text and external sources, include it in both lists.
- Ignore or exclude speculative questions lacking enough context to answer meaningfully.
User Query: {text}
After this analysis, return the result in this strict JSON format:
{{
"rag_queries": ["query1", "query2"],
"general_queries": ["query1", "query2"],
"context": "relevant context from the input"
}}
"""
def create_template(self, text: str) -> str:
return self.prompt.format(text=text)
So, somehow, this structure worked and scaled (somehow). I knew that relying on plain-text prompts wasn’t enough. If I wanted reliable outputs, I had to control the structure of the model’s responses. So I used Pydantic with the Instructor to enforce JSON-based outputs.
This allowed me to define structured LLM responses while using exponential backoff to handle API failures. Here’s what my setup looked like:
llm.py
import instructor
from langfuse.openai import OpenAI
# from openai import OpenAI
from pydantic import BaseModel
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
)
from retrieval.core.interfaces import BasePromptTemplate
class LLMInterface(ABC):
def __init__(self, model: str):
self.model = model
@abstractmethod
def get_answer(self, prompt: str, *args, **kwargs):
pass
class Gpt(LLMInterface):
def __init__(self, model: str):
self.model = model
self.llm = instructor.from_openai(OpenAI())
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
def completion_with_backoff(self, llm, **kwargs):
return llm.chat.completions.create(**kwargs)
def get_answer(
self,
prompt: BasePromptTemplate,
formatted_instruction: BaseModel,
temperature=0,
*args,
**kwargs,
):
formatted_prompt = prompt.create_template(*args, **kwargs)
answer = self.completion_with_backoff(
llm=self.llm,
model=self.model,
temperature=temperature,
response_model=formatted_instruction,
messages=[
{
"role": "user",
"content": formatted_prompt,
},
],
)
if formatted_instruction:
return answer.dict()
else:
return answer.choices[0].message.content
query_components.py
class QueryComponents(BaseModel):
rag_queries: List[str] = Field(
...,
description=(
"List of queries that require searching through provided documents or context. "
"These queries will be processed using the RAG (Retrieval Augmented Generation) system."
),
examples=[
[
"Extract specifications from the email",
"Find delivery terms in the contract",
]
],
)This approach had clear advantages:
✅ Controlled outputs: Using Pydantic meant that I always got structured JSON instead of unpredictable free-text responses.
✅ API robustness: Exponential backoff ensured that my system could recover from API failures gracefully.
✅ Encapsulation: I built an abstraction (LLMInterface) so I could swap out different models if needed.
But there were clear disadvantages too:
🚨 Too many hardcoded prompts
I had to write a new template manually whenever I needed a new prompt. This made iterating on prompts slow and tedious.
🚨 Prompt optimization was manual
If the model’s response quality was bad, I had no automated way to improve the prompt, I had to tweak it by trial and error.
🚨 No fine-tuning mechanism
Since everything was prompt-based, I had no way to adapt or optimize prompts based on real-world performance dynamically.
🚨 Difficult debugging & versioning
If a prompt suddenly stopped working well, I had no idea why. Was it the model? The API? The prompt itself? Debugging was painful.
3.2. DSPy Paradigm: Let’s program — not prompt — LMs
As their value proposition says, “Programming—not prompting—LMs.”
DSPy is a framework designed for programming, not just prompting, language models. It enables rapid iteration in developing modular AI systems and provides algorithms to optimize both prompts and model weights. Whether you're creating basic classifiers, advanced RAG pipelines, or complex agent loops, DSPy streamlines the process.
And let’s be honest: Declaring the output structure with Pydantic in a schemas.py, which is decoupled from the initial prompt, wastes a lot of time.
DSPy aims to shift the focus away from endlessly tweaking individual LLM parameters and toward designing a strong overall system.
But how do we do that?
Think of LLMs as devices that follow instructions, similar to how deep neural networks work. For example, in PyTorch, you define a convolution layer that processes inputs from previous layers. You don’t need to worry about low-level details like CUDA cores; everything is handled within that layer's abstraction.
In the same way, DSPy treats LLMs as modular components. Without micromanaging every detail, you can stack these modules in different combinations to achieve the desired behavior, whether for chain-of-thought reasoning, ReAct, or other approaches.
To get the desired behavior, we need to change a few things:
Handwritten promptsSignaturesPrompt techniques and prompt chainsModulesManual prompt engineeringOptimizers (Still investigating this feature)
Dspy ~ Pytorch
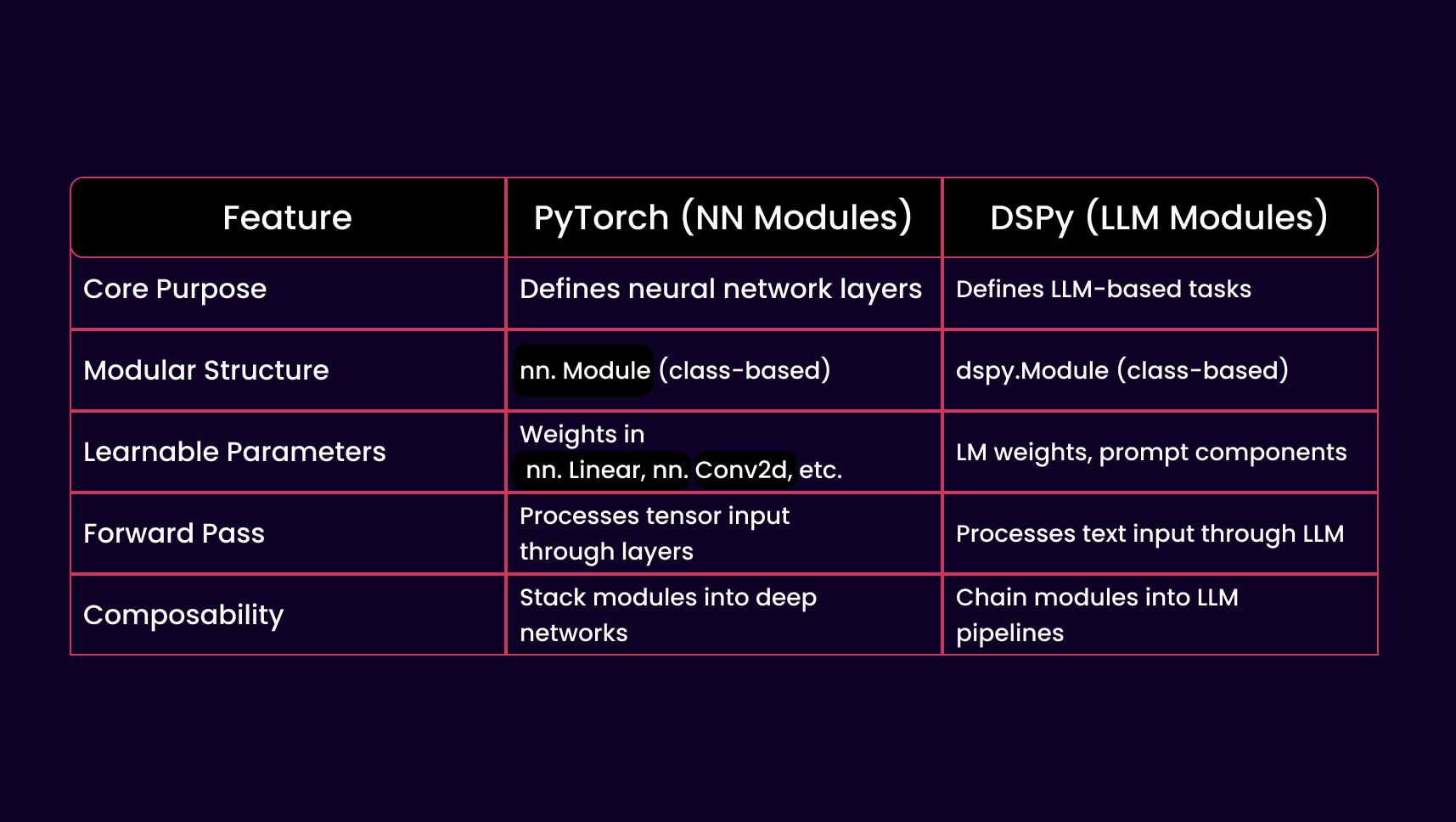
Remember the days when GenAI wasn’t so hyped and our daily work involved implementing neural networks (NN) or convolutional neural networks (CNN)?
Or the day when we switched Tensorflow with Pytorch?
Dspy took a lot of inspiration from Pytorch.
Both PyTorch and DSPy use a modular design to structure computation:
In PyTorch, modules represent layers in a neural network.
In DSPy, modules represent LLM-powered reasoning units.

Dspy Signatures
In DSPy, you must include a signature every time you call the LM.
“A signature is a declarative specification of input/output behavior of a DSPy module. Signatures allow you to tell the LM what it needs to do, rather than specify how we should ask the LM to do it” state the docs.
A Signature is just a structured way of telling the LM what you want it to do. It includes three key parts:
A concise description of the sub-task the LM needs to solve.
A definition of the input fields, like a question or any other data you feed in.
A description of the expected output, such as the LM's answer or structured response.
For example, you can create a signature that takes a long snippet from a PDF and extracts structured information from it.
class BasicQA(dspy.Signature):
"""Answer questions with short factoid answers."""
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")Personal opinion:
I don’t like the approach of writing the instructions into the class docstrings.Docstrings were created for another purpose, but in the next section, I will show you how I injected the instructions through a decorator because, in the future, we want to do versioning on that prompt/instructions.
Dspy modules
Modules in DSPy are flexible building blocks with learnable parameters, including prompt components and LM weights. They work as callable classes, meaning you can pass inputs to them and get structured outputs in return.
Since they’re modular by design, you can combine multiple modules to create larger, composable pipelines, just like PyTorch uses NN modules for deep learning. DSPy takes that same concept and applies it to LLM-driven workflows.
Think of modules as plug-and-play components that simplify complex prompting strategies. You can use existing modules or create your own to build custom data pipelines. They can work independently or be chained together for more sophisticated tasks.
For example, you can define a standalone ChainOfThought module using DSPy’s shorthand Signature notation.
class ChainOfThought(dspy.Module):
def __init__( self, signature):
super().__init__()
self.predict = dspy.Signature(signature)
# overwrite the forward function
def forward(self, **kwargs):
return self.predict(**kwargs)
# create an instance of class with shorthand Signature notation
# as argument
cot_generate = ChainOfThought(“context, question → answer”)
# call the instance with input parameters specified in the
# signature
response = cot_generate(“context=....”,
“question=How to compute area of a triangle with height 5 feet and width 3 feet.”
print(f”Area of triangle: {response.answer}”)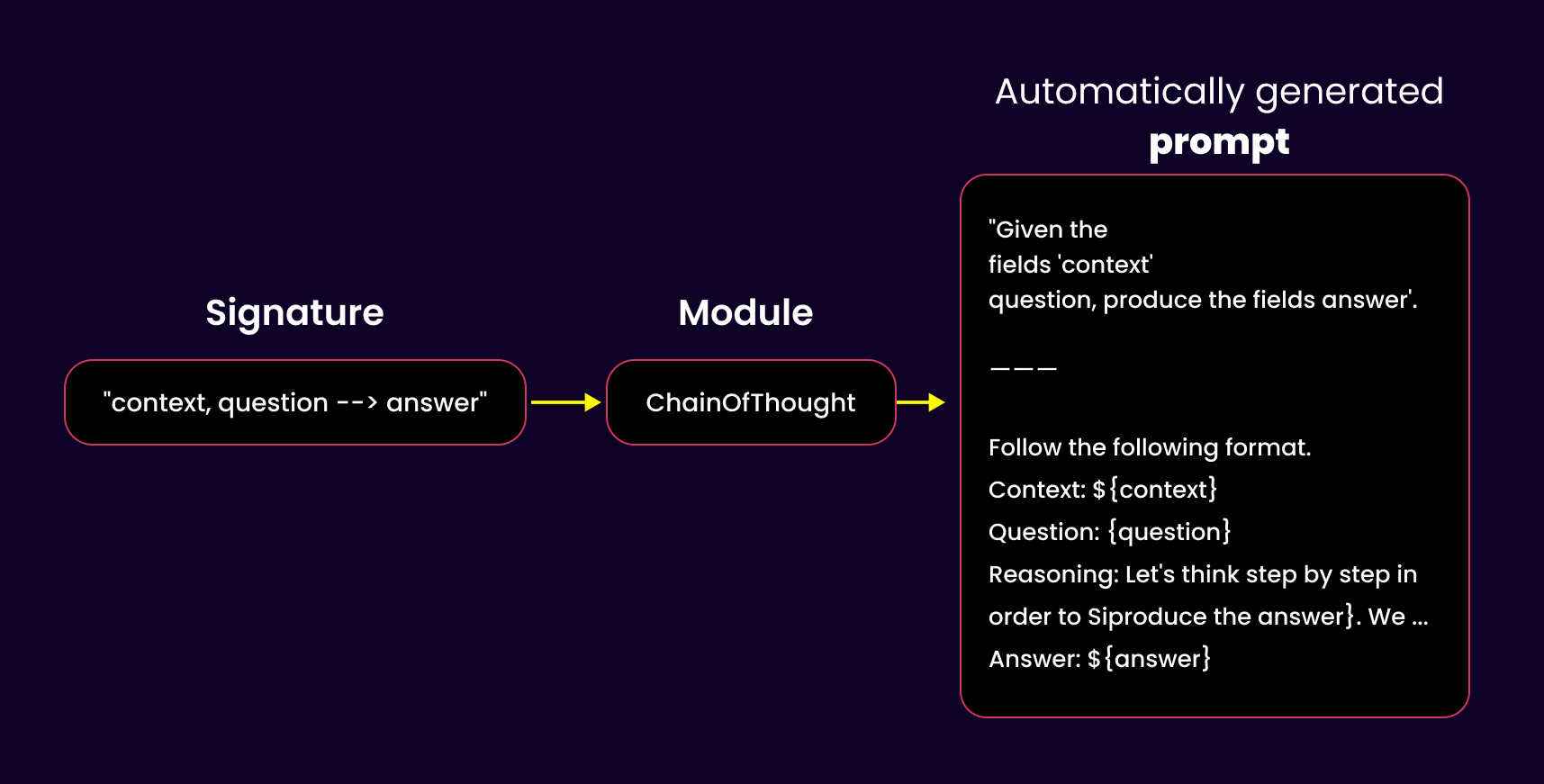
DSPy modules let you define your task logic in a declarative way, focusing on what needs to be done, not how to do it. They encapsulate behavior, input/output formats, style, and any custom logic, eliminating the need for long, complex prompts or endless trial and error. Instead of crafting intricate prompts, you can build structured flows using modular, composable blocks, making your LLM interactions more scalable and maintainable.
Dspy optimizers
DSPy optimizers, also called "teleprompters," are designed to improve your program by tweaking prompts or adjusting LM weights to maximize a given metric. They can analyze your data, simulate execution traces to create good/bad examples, refine step-by-step instructions based on past outcomes, fine-tune your LM with self-generated examples, or mix and match these approaches to enhance quality or reduce costs.
Each teleprompter balances cost and quality differently, depending on what you need. A good starting point in DSPy is BootstrapFewShot, a straightforward default optimizer.
More about optimizers and practical implementation will be described in Part 2.
4. Practical case study → create a summary of a long document
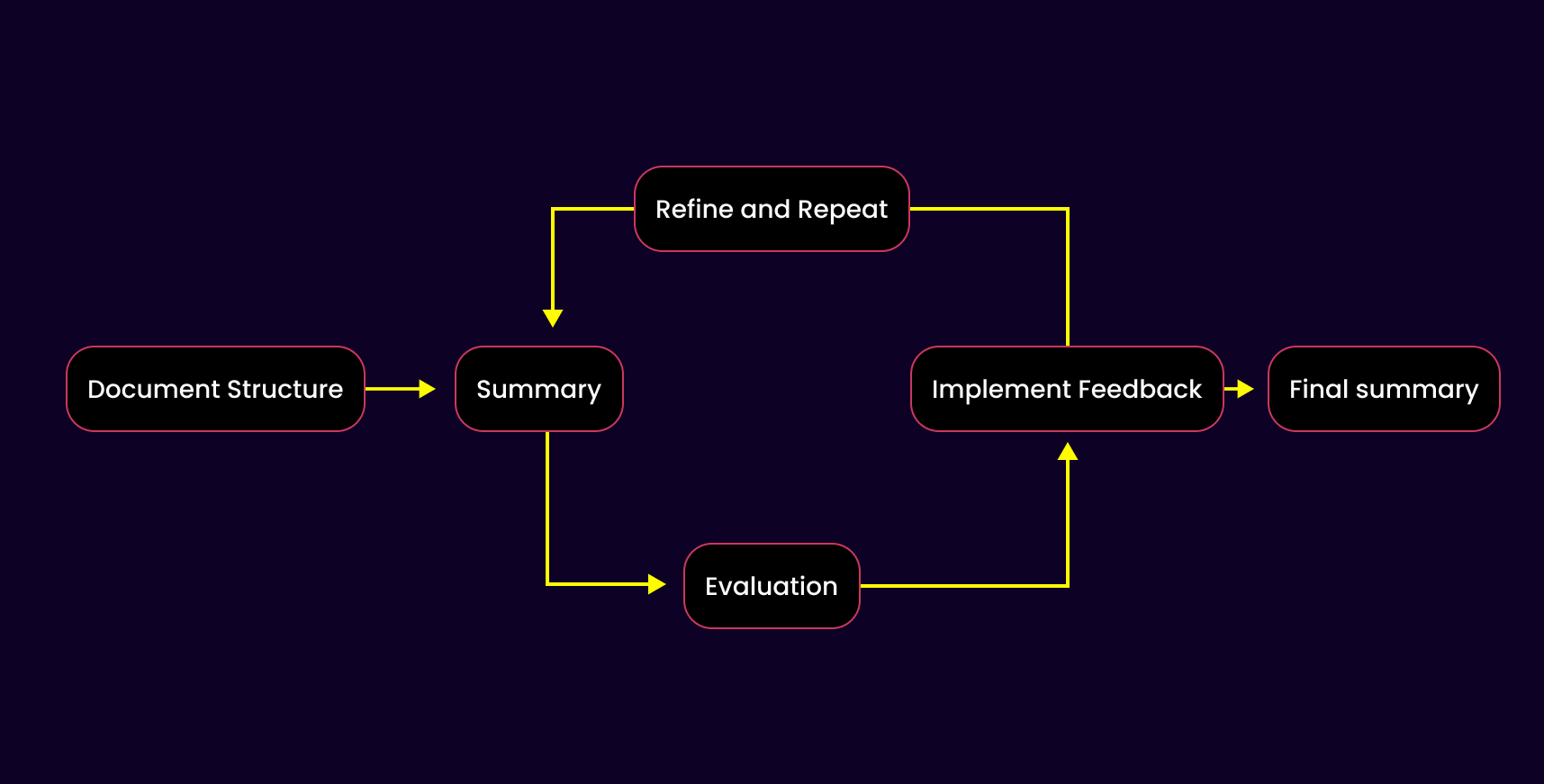
Problem statement: The summary of a long document is one of the oldest problems in the NLP field. In this section I will show you how I solved this problem with Dspy, using signatures, modules and optimizers.
The summary flow is built from multiple components:
Create structure signature – Defines how documents are segmented.
Summary signature – Summarizes each document component.
Evaluation signature – Evaluate the generated summaries.
Implement feedback signature – Refines summaries based on the evaluation.
Pipeline flow – Shows how all these components connect.
Before diving into how I declared the signatures and pipeline, I told you that Dspy has the concept of instructions in the docstrings class.
I changed the scope here a bit and created a decorator that automatically injects the instructions/prompt into the signature.
This is because, in the future, I would like to version the instructions/prompt with an observability tool like Langsmith, for example.
decorator.py
def dynamic_class_docstring(doc_template):
"""Decorator to dynamically generate a class docstring."""
def decorator(cls):
cls.__doc__ = doc_template.format(class_name=cls.__name__)
return cls
return decorator
The DocumentStructure signature identifies the document's structure, headers, and subheaders. Here, instead of short instructions, I injected an entire prompt (document_structure_prompt).
prompts/document_structure.py
document_structure_prompt = """
You are provided with the text of a document. Identify all headings and any subheadings, then produce a valid JSON object reflecting this structure. For each heading (and subheading), provide:
1. A "sectionTitle" field containing the heading text.
2. A "subsections" array for deeper levels of headings, if any.
**Output Requirements:**
- Output must be valid JSON (no extra text, no code blocks, no commentary).
- The top-level JSON must have a "documentTitle" field (either extracted from the document or set to a generic placeholder if no title is found).
- Include a "sections" array at the top level, where each element is an object representing a main heading.
- Each main heading object must contain:
- "sectionTitle": The text of the heading
- "subsections": An array (possibly empty) of subheadings that follow the same structure (recursive nesting if needed).
- Do not include any summary or additional keys.
Below is an example of the desired JSON structure (no summaries included):
{{
"documentTitle": "Example Document Title",
"sections": [
{{
"sectionTitle": "1. Introduction",
"subsections": []
}},
{{
"sectionTitle": "2. Main Topic",
"subsections": [
{{
"sectionTitle": "2.1 Subtopic A",
"subsections": []
}},
{{
"sectionTitle": "2.2 Subtopic B",
"subsections": []
}}
]
}}
]
}}
"""
signatures/document_structure.py
import dspy
from retrieval.document.analysis.summarization.prompts.document_structure import (
document_structure_prompt,
)
from retrieval.document.analysis.utils import dynamic_class_docstring
@dynamic_class_docstring(document_structure_prompt)
class DocumentStructure(dspy.Signature):
text = dspy.InputField()
document_structure: dict = dspy.OutputField(
desc="valid JSON object reflecting the document structure"
)What I really like about Dspy is the simple way of using any LLM with your signature.
class Summarize(dspy.Module):
def __init__(self):
# Define LLMs for each submodule
self.llm_structure = dspy.LM(
"o1-mini",
api_key=os.getenv("OPENAI_API_KEY"),
temperature=1,
max_tokens=20000,
cache=False,
)
self.llm_summary = dspy.LM(
"o1-mini",
api_key=os.getenv("OPENAI_API_KEY"),
temperature=1,
max_tokens=20000,
cache=False,
)
self.llm_evaluation = dspy.LM(
"openai/gpt-4o-mini",
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0,
max_tokens=16000,
cache=False,
)
self.llm_final_summary = dspy.LM(
"openai/gpt-4o-mini",
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0,
max_tokens=16000,
cache=False,
)Then, in the forward method, we call it dspy context and set the llm on each signature.
def forward(self, text: str):
logging.info("Starting document structure analysis")
with dspy.context(lm=self.llm_structure):
logging.info("Configuring summary context with o1-mini")
document_structure = self.document_structure(text=text)
logging.info("Starting document summarization")
with dspy.context(lm=self.llm_summary):
summary = self.summarize(text=text, document_structure=document_structure)
logging.info("Starting summary evaluation")
with dspy.context(lm=self.llm_evaluation):
evaluation = self.evaluation(
text=text, document_structure=document_structure, summary=summary
)
logging.info("Starting final summary generation")
with dspy.context(lm=self.llm_final_summary):
final_summary = self.feedback_loop(
text=text, summary=summary, feedback=evaluation
)If you want to see what happens behind the scenes, we can call dspy.inspect_history(), and see how dspy build the prompt for us, by respecting the signature and also our prompt.
System message:
Your input fields are:
1. `text` (str): full text of the document
2. `summary` (str): summary of the document
3. `feedback` (str): feedback on the summary that musst be applied on the inital summary
Your output fields are:
1. `reasoning` (str)
2. `final_summary` (dict): final summary of the document after applying the feedback in a valid JSON object respecting the document structure
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## text ## ]]
{text}
[[ ## summary ## ]]
{summary}
[[ ## feedback ## ]]
{feedback}
[[ ## reasoning ## ]]
{reasoning}
[[ ## final_summary ## ]]
{final_summary} # note: the value you produce must adhere to the JSON schema: {"type": "object"}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
You are given a summary of a document and a feedback.
Your task is to rewrite the summary based on the feedback.
Instructions:
- Carefully review the feedback.
- Update the summary to incorporate all suggested improvements.
- Maintain the original logical structure while enhancing clarity and precision.
- Use bullet points and bold headings for readability.
- Avoid redundancy.
- Based on the full text of the document, include all the details that are missing in the summary based on the feedback.
User message:
[[ ## text ## ]]
Document text
[[ ## summary ## ]]
Prediction(
reasoning='I will read through the contract text and extract the key information from each section and subsection, as defined by the document structure. I will then create a JSON object containing a summary of each section and subsection. The summaries will be concise and informative, avoiding unnecessary details.',
summary={'documentTitle': 'Doc Title', 'sections': [{'sectionTitle': 'Title 2', 'summary': 'This section identifies the parties involved in the contract}
[[ ## feedback ## ]]
Prediction(
reasoning='The summary provided captures the essential elements of the contract, including the parties involved, the object of the contract, duration, service provision, payment terms, obligations of both parties, intellectual property rights, confidentiality, and termination conditions. However, there are areas for improvement in terms of completeness and conciseness. While the summary is generally accurate, it could benefit from more detailed coverage of specific obligations and rights, particularly in sections like "Obligatiile Partilor" and "Drepturile de Proprietate Intelectuală." Additionally, some summaries could be more concise by avoiding repetitive phrases and ensuring clarity without excessive detail.',
evaluation={'accuracy': {'score': 35, 'feedback': 'The summary accurately reflects the main points of the contract, but some details are either omitted or not fully explained, particularly in the obligations and rights sections.'}, 'completeness': {'score': 25, 'feedback': 'While the summary covers the main sections, it lacks depth in certain areas, such as the specific obligations of the parties and the implications of the intellectual property rights.'}, 'conciseness': {'score': 15, 'feedback': 'Some sections could be more concise. For example, the summaries for obligations could be streamlined to avoid redundancy.'}, 'readability': {'score': 8, 'feedback': 'The summary is generally easy to read, but some complex sentences could be simplified for better understanding.'}}
)
Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## final_summary ## ]]` (must be formatted as a valid Python dict), and then ending with the marker for `[[ ## completed ## ]]`.5. Conclusion
We’ve explored how traditional prompt engineering, while effective in simple cases, quickly falls apart when scaling to production. Hardcoded templates, manual tweaking, and lack of structured optimization make it a fragile approach. DSPy changes the game by treating prompts as structured programs, bringing modularity, optimization, and reproducibility to the process.
But we’re only scratching the surface. In Part 2, we’ll take things further with a fully functional, end-to-end example, showing you how DSPy enables dynamic prompt optimization, structured output control, and automated evaluation loops.
If you’re tired of guessing what works and want a systematic, scalable approach to prompt engineering, Part 2 is where the real magic happens.